排序和去重是数据分析中对数据常见的两种操作。
排序
简介
在 algorithm 头文件里,有一个 sort 函数,十分的方便。
运用了快速排序,其基本思想是分治,也可以加上二分的优化;
速度很快,达到 。
至少比冒泡快多了。
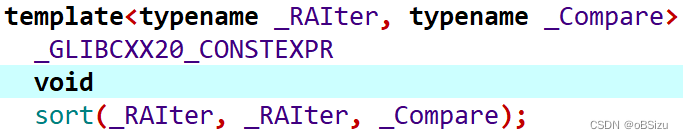
函数有三个参数:sort(start, end, cmp)。
start 是排序起始地址,end 是排序结束地址的下一位。
cmp 支持用户自定义排序方法,也可以不填,就默认升序。
实际应用
具体地,我有一个数组 。对它进行以下操作:
int n, a[114514];
cin >> n;
for(int i = 1; i <= n; i++){
cin >> a[i];
}
没错,其实就是个输入。
现在,输入的这些数据无序,如何让他们升序排列?
sort(a + 1, a + n + 1);
起始下标是 ,所以第一个参数是 。
终止下标是 ,所以第二个参数是 。
当然你也可以多加一个取址:
sort(&a[1], &a[n + 1]);
两种方法等价。
快速排序是通过比较的方式来排序。
类比于刚刚的方法,降序排列就需要使用自定义 cmp 来实现。
定义一个 bool 函数,名字随意,参数是要比较的两个东西:
bool jntm(int kun1, int kun2){ // 瞎起名字
/*
返回 true → 后面的放在前面
返回 false → 不动
*/
return kun1 > kun2; // 较大的放在前面
}
sort(a + 1, a + n + 1, jntm);
这个函数如果要是全部返回 true 值的话,整个数组将会以最中间的元素左右对称;如果全部返回 false 的话,整个数组不变。bool 的函数默认返回 false。
因此,如果想要实现排序的效果,需要比较前一个和后一个。
问题来了,如果对于一个 struct 结构体,cmp 如何使用?
【奖学金】

// Author:PanDaoxi
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
const int INF = 301;
struct stu{
int id, total, s1, s2, s3;
} a[INF]; // 结构体数组
int n;
bool cmp(stu x, stu y){ // 比较函数
if(x.total != y.total) return x.total > y.total; // 先按总分降序排列
else if(x.s1 != y.s1) return x.s1 > y.s1; // 再按照语文成绩降序排列
else return x.id < y.id; // 最后是学号
}
int main(){
ios :: sync_with_stdio(false);
cin >> n;
for(int i = 1; i <= n; i++){
a[i].id = i; // 记录学号
cin >> a[i].s1 >> a[i].s2 >> a[i].s3;
a[i].total = a[i].s1 + a[i].s2 + a[i].s3; // 计算总分
}
sort(a + 1, a + n + 1, cmp); // 排序
for(int i = 1; i <= 5; i++){ // 输出
cout << a[i].id << " " << a[i].total << endl;
}
return 0;
}
去重
集合()——升序排序 去重
对于数据规模较小的一组数,我们可以通过桶排序的方法去重。简单快捷,好写。
推广到一般情况,有的时候字符串 生成的数会很大(或者本身的数据规模就很大),这时候就不能再利用桶了,可能会爆空间。
有一种数据集——集合 可以一边升序排序,一边去重。
头文件:set。
同样,我有一个数组 ,离线输入了一些数据。
int n, a[114514];
cin >> n;
for(int i = 1; i <= n; i++){
cin >> a[i];
}
我们就可以创建一个整数型集合储存、去重。
set <int> s(a + 1, a + n + 1);
for(auto i : s){
cout << i << " ";
}
// 也可以创建一个迭代器,但是我不喜欢,因为太麻烦,也可以直接用 auto 代替
for(set <int> :: iterator i = s.begin(); i != s.end(); i++){
cout << *i << " ";
}
// 倒着遍历
for(auto i = s.rbegin(); i != s.rend(); i++){
cout << i << " ";
}
// 转存到 vector
vector <int> v(s.begin(), s.end());
for(auto i : v){
cout << i << " ";
}
函数——只去重
头文件:algorithm。
本质是将重复的元素移动到数组的末尾,最后再将迭代器指向第一个重复元素的下标。
这个移动的过程也需要比较。
int n, a[114514];
cin >> n;
for(int i = 1; i <= n; i++){ // 还是照常的输入
cin >> a[i];
}
// 一般使用前需要先排序!!
sort(a + 1, a + n + 1);
// 获取去重后数组的新长度
int len = unique(a + 1, a + n + 1) - a - 1;
// 输出
for(int i = 1; i <= len; i++){
cout << a[i] << " ";
}
如果使用前需要先排序,那么就出现了一个新问题——如何按照输入顺序?
——可以通过结构体解决。
const int INF = 114514;
struct node {int num, id;} a[INF];
bool cmp(node kun1, node kun2){
return kun1.id < kun2.id; // 输入早的放在前面
}
// ......
int n;
cin >> n;
for(int i = 1; i <= n; i++){
cin >> a[i].num;
a[i].id = i; // 记录输入顺序
}
sort(a + 1, a + n + 1);
int len = unique(a + 1, a + n + 1) - a - 1;
// 再次排序(按照输入顺序)
sort(a + 1, a + len + 1, cmp);
// 输出
for(int i = 1; i <= len; i++){
cout << a[i].num << " ";
}
美滋滋写完,发现编译器报错:
[Error] no match for 'operator==' (operand types are 'node' and 'node')
[Error] no match for 'operator<' (operand types are 'node' and 'node')
为啥?咋嘛咋嘛滋味儿,我突然发现结构体有两个变量。
电脑和 unique 函数咋知道我要比较哪个?
好的,它不知道,那咱们帮它知道。一拳头淦电脑上。
通过重载运算符:
struct node {
int num, id;
bool operator == (node k){ // 判等,判的是储存的数等
return num == k.num;
}
bool operator < (node k){ // 排序,让数小的在前面,让输入编号小的在前
return num < k.num || num == k.num && id < k.id;
}
} a[INF];
如果有更多的结构体成员也没关系,核心就是两次排序和重载运算符。
现在就可以实现不排序的去重了。
题
【模板】字符串哈希

很简单的水了一道题。(喜)
// Author:PanDaoxi
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
const int INF = 1e4 + 1;
set <string> s;
int main(){
ios :: sync_with_stdio(false);
int n;
cin >> n;
while(n--){
string str;
cin >> str;
s.insert(str);
}
cout << s.size();
return 0;
}